Web Scraping (Python) ด้วย beautifulsoup และ requests
S T A C K P Y T H O N-
 Sonny
Sonny
- Dec. 4, 2020

Web Scraping เป็นอีกหนึ่งทักษะที่ถูกพูดถึงบ่อย ๆ สำหรับสายงานด้านโปรแกรมมิ่งและด้าน วิเคราะห์ข้อมูลยิ่งถ้าเหล่าสาวก Python นั้น จะได้ยินคำนี้บ่อย ๆ โดยบทความนี้เราจะมา set zero และเรียนรู้ สอนใช้งานและทำความเข้าใจไปพร้อม ๆ กันว่า จริง ๆ แล้ว Web Scraping มันคืออะไร เอาไปใช้งานยังไง ทำได้อย่างไร กฏหรือข้อจำกัดในการ scrape ข้อมูลมีอะไรบ้าง ทำแล้วจะโดนเจ้าของเว็บไซต์บล็อกหรือไม่ เอาให้เข้าใจกันแบบหมดจดในเกือบทุกมิติ
Web Scraping คืออะไร ?
Web Scraping คือวิธีการในการดึงข้อมูลจากหน้าเว็บเพจหรือเว็บไซต์ โดยใช้ภาษาโปรแกรมมิ่งเป็นเครื่องมือ (ในที่นี้คือภาษา Python) ในการเขียนสคริปต์ในการดึงข้อมูลจากหน้าเว็บไซต์นั้น ๆ โดยภาษาที่นิยมก็อย่างเช่น Scripting Language เช่น ไพธอน ซึ่งเมื่อทำการดึงข้อมูลเสร็จแล้ว ก็จะมีขั้นตอนในการสกัด (Extract) เอาเฉพาะข้อมูลที่ต้องการ โดยเก็บไว้ในฟอร์แมตรูปแบบต่าง ๆ เพื่อนำไปใช้งานต่อไป โดยปกตินั้นวิธีการในการดึงข้อมูลจาก Data Sources หรือแหล่งข้อมูลต่าง ๆ มีอยู่หลัก ๆ ดังนี้
ปกติการดึงข้อมูลนั้นมีอยู่ด้วยกัน 2 วิธีหลัก ๆ คือ
- ดึงจาก API
- ทำ web scraping
1. ดึงจาก API
การดึงข้อมูลโดยใช้ API (Application Programming Interface) นั้นเป็นวิธีที่หลาย ๆ คนคงจะเคยได้ยินและคุ้นเคยเป็นอย่างดี (ถึงแม้จะเคยทำหรือไม่ แต่ส่วนใหญ่ก็คงจะได้ยินและรู้จัก API กันหมด) ซึ่งการดึงข้อมูลโดยวิธีนี้ก็จะมี API Web Service ที่เป็นแหล่งของข้อมูลนั้น ๆ และเปิดเป็นแบบ Open API ให้เราใช้งาน ซึ่งมีทั้งฟรีและเสียตังค์ อาจจะขึ้นอยู่กับจำนวน Requests ตัวอย่างการดึงข้อมูลแบบ API เช่น ดึงข้อมูลสภาพอากาศจากทั่วโลกโดยใช้ openweathermap.org มาแสดงผลไว้ที่หน้าเว็บไซต์ของเรา หรือเช่น กรมควบคุมโรค กระทรวงสาธารณะสุขเปิด Open API ให้มีสามารถดึงข้อมูล Covid-19 ได้ เป็นต้น เหล่านี้ก็คือตัวอย่างภาพรวมแบบคร่าว ๆ ของการใช้งาน API
2. ทำ web scraping
ซึ่งการทำ Web Scraping นั้นก็คือวิธีการที่เราจะมาทำความเข้าใจและเขียนโค้ดเพื่อใช้งานในวันนี้กัน โดยใน Part 1 นี้จะเป็น Overview หรือเน้นให้เห็นภาพรวมของการทำ Web Scraping ในทำนอง Web Scraping 101 - Introduction ประมาณนี้ ซึ่งหลังจากจบ Part นี้แล้ว ก็จะเป็น Part 2 และ 3 กันต่อ เริ่มจาก Beginner ไปจนถึงขั้น Intermediate เช่นการเข้าถึง คลาส CSS ต่าง ๆ ที่เริ่มซับซ้อน และการประยุกต์ใช้ Regular Expression หรือที่มักเรียกกันสั้น ๆ ว่า Regex เข้ามาเพื่อช่วยให้สามารถค้นหาข้อมูลได้สะดวกยิ่งขึ้น
"ในบทความนี้หลายคนอาจจะงงสำหรับภาพหน้าปกที่เป็นรูปอวนสำหรับหาปลาที่อยู่บนเรือ และมีคำถามว่ามันเกี่ยวอะไรกับ Web Scraping โดยผู้เขียนขอนำขั้นตอนในการหาปลามาเปรียบเทียบเพื่อให้บทความนี้ อ่านสนุกและน่าสนใจมากยิ่งขึ้น"
แนะนำบทความ: Web Scraping ด้วย Python (สำหรับเว็บที่ต้อง login)
ตัวละครเอกในเรื่องนี้
- Data = ปลา
- Web Scraper = คนหาปลา
- Webpage, Website = ทะเล (แหล่งหาปลา)
- Scraping = การหาปลา (รวมไปถึงเครื่องมือที่ช่วยหาปลาเช่น requests, BeautifulSoup ซึ่งเปรียบเสมือนอวนหาปลา)
- Data Format (File) = CSV คือเครื่องมือเก็บปลา
- Data Visualization = การนำปลาไปปรุงอาหาร
จุดประสงค์
- เข้าใจและอธิบายได้ว่า web scraping คืออะไร
- เข้าใจและสามารถอธิบายได้ว่าทำไมต้องมีการทำ web scraping
- เข้าใจและอธิบายประโยชน์ในการทำ web
scraping ได้
- สามารถนำการทำ web scraping ไปประยุกต์ใช้งานได้
- เข้าใจและอธิบายได้ว่าเว็บไซต์หรือแหล่งข้อมูลนั้นมีข้อจำกัดหรือข้อกำหนดการใช้งานข้อมูลของเว็บนั้น
- เข้าใจและอธิบายได้ว่าเครื่องมือหรือไลบรารีที่ใช้สำหรับการทำ
Web Scraping มีอะไรบ้าง
- สามารถใช้งาน beautifulsoup
library ได้
Software & Tools
- Python version 3 +
- PyCharm (IDE)
- BeautifulSoup (Web scraping library)
- requests library
- csv library
ทำไมต้องทำ web scraping ?
ในโลกแห่งความเป็นจริง ข้อมูลไม่ได้ถูกจัดฟอร์แมตมาให้พร้อมใช้งานเสมอไปหรือเป็นข้อมูลที่ไม่ได้มีโครงสร้าง (Unstructured Data) ดังนั้นข้อมูลจึงมีอยู่กระจัดกระจายทั่วไปตามเว็บ และเว็บไซต์ส่วนใหญ่ก็คงไม่ได้ใจดีถึงขนาดทำเป็นไฟล์ในฟอร์แมตต่าง ๆ เช่น CSV, JSON, Text, Excel, SQL, etc ไว้ให้เราได้ทำการดาวน์โหลดมาใช้ฟรี ๆ ดังนั้น web scraping ก็คือพระเอกที่จะมาช่วยจัดการปัญหาเหล่านี้
ข้อดีของการทำ web scraping
- ดึงข้อมูลได้ฟรี มีแหล่งข้อมูลมากมายบนโลกนี้ที่เปิดให้ดึงข้อมูล
- สามารถนำข้อมูลที่ได้ไปวิเคราะห์และใช้งานได้ต่อไป
- สามารถรับงานเป็นจ็อบ ๆ ในการดึงข้อมูลได้
- ถึงแม้ web scraping จะไม่ใช่งานหรืออาชีพโดยตรง แต่ถ้ามีสกิลด้านนี้ จะทำให้เราเป็นหนึ่งในตัวเลือก (Candidate) ในการสมัครงาน ได้เป็นอย่างดี
ข้อจำกัดของการทำ web scraping
- ถ้าเว็บไซต์ที่เราทำการดึงข้อมูลเปลี่ยนโครงสร้างหน้าเว็บ จะทำให้การ Scrape ข้อมูลหยุดชะงักลงทันที และต้องมีการเขียนเพื่อแก้สคริปต์เข้าไปใหม่ (แต่จริง ๆ แล้วไม่ค่อยเปลี่ยนกันกระทันหันหรอกครับ)
- ข้อมูลหลายส่วนถูกจำกัด หลาย ๆ เว็บก็ไม่สามารถที่จะ Scrape ข้อมูลได้ ซึ่งสุดท้ายถ้าข้อมูลนั้นไม่เปิดให้ทำ Web Scraping ก็จะต้องเรียกใช้บริการ API แทน
งาน web scraping
ถึงแม้งานด้าน web scraping จะได้มีตำแหน่งงานสำหรับ web scraper ที่ระบุชัดเจน และผู้เขียนได้ทำการทดสอบพิมพ์ใน Google ด้วยคีย์เวิร์ดคำว่า "งาน web scraping" และก็อย่างที่คิด คือไม่พบตำแหน่งงานด้านนี้ที่ระบุชัดเจน แต่ไปเจองานในหน้าเว็บหางาน Freelance ที่หลาย ๆ คนคงรู้จักกันดี น้่นก็คือ Fastwork และพบว่าใน Fastwork มีผู้ที่รับงานเกี่ยวกับการทำ web scraping อยู่ประมาณ 11 คน เรตราคาก็เริ่มต้องแต่ 1,500 - 3,000 บาท ต่องาน น่าสนใจไม่น้อย รายได้ก็ถือว่าโอเครเลย หรือถ้าท่านใดอยากจ้างผู้เขียนก็ติดต่อเข้ามาได้ครับ (เนียน ๆ)
ลองเข้าดูใน fastwork-web-scraping
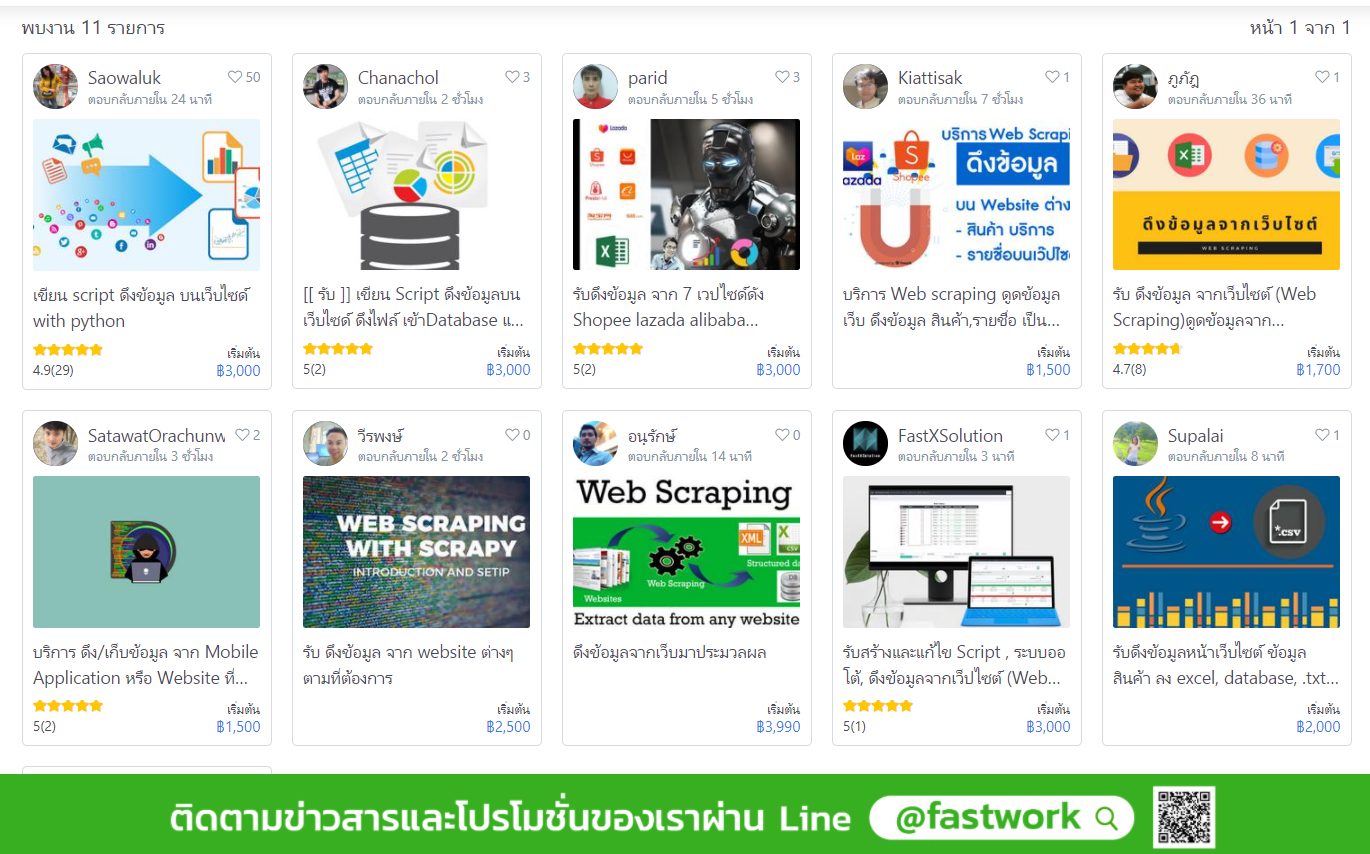
งาน web scraping ในเว็บไซต์ Fastwork
web scraping มีแค่เฉพาะภาษาไพธอน ?
ยังมีหลายคนที่ยังเข้าใจว่า web scraping นั้น ทำได้เฉพาะภาษาไพธอน ซึ่งจริง ๆ แล้วการทำ web scraping นั้น ไม่ได้จำกัดอยู่แค่ในภาษาไพธอน ยังสามารถทำได้ในภาษาโปรแกรมมิ่งอื่น ๆ ไม่ว่าจะเป็น R, JavaScript, Java, Go, PHP, etc เพียงแต่ว่า ภาษาไพธอนเป็นที่นิยมที่สุด ในการทำงานด้าน web scraping
สิ่งที่ต้องรู้ก่อนทำ web scraping
ในการทำ web scraping นั้นนอกจากเป้าหมายการทำ และพื้นฐานด้านโปรแกรมมิ่งเบื้องต้นแล้ว ต้องตรวจสอบและศึกษาให้ดีด้วยก่อนครับว่า เว็บไซต์เป้าหมายของเรานั้น เขามี Policy หรือนโยบายเกี่ยวกับข้อมูลอย่างไร ไม่งั้นอาจจะกลายเป็นการละเมิดแทน
โดย สิ่งที่ควรรู้ในการทำ Web Scraping ก็คือ
- เป้าหมายของการทำ web scraping
- เว็บไซต์ไหนที่สามารถ Scrape ข้อมูลได้บ้าง
- พื้นฐาน Python เบื้องต้น
- พื้นฐาน HTML เบื้องต้น
1. เป้าหมายของการทำ web scraping
อันนี้แทบจะเรียกได้ว่ามาอันดับแรกสุด ถ้าไม่มีเป้าหมาย ก็ไม่รู้ว่าจะทำไปทำไม ใช่หรือไม่ ? ดังนั้นจึงต้องตั้งเป้าหมายกันก่อนว่าจะเอาไปทำอะไร เช่น เอาข้อมูลที่ได้ไปทำ Data Analysis, Data Visualization, Dataset สำหรับทดสอบโมเดล Machine Learning, etc
2. เว็บไซต์ไหนที่สามารถ scrape ข้อมูลได้บ้าง ?
แน่นอนว่ามันก็มีวิธีการสังเกตอยู่ว่าเว็บไหนที่เราสามารถทำ web scraping ได้ โดยเบื้องต้นให้สังเกตที่ Terms of Service, Privacy Policy, etc เหล่านี้คือคีย์เวิร์ดที่เป็นที่สังเกตและเราต้องเข้าไปอ่านข้อกำหนดของเว็บต่าง ๆ เหล่านี้ให้ดี
3. พื้นฐาน Python เบื้องต้น
ข้อนี้คงไม่มีปัญหา เชื่อว่าหลาย ๆ คนที่ได้อ่านบทความนี้ส่วนใหญ่ก็คงจะผ่านการเรียน Python กันมาเรียบร้อยแล้ว ยกตัวอย่างโค้ดด้านล่างแบบง่าย ๆ ธรรมดา ๆ ถ้าสามารถอ่านโค้ดและรู้ output คุณได้ไปต่อ !
print("Hello, world")
# Output 1 ?
num1 = 20
num2 = "20"
num3 = num1 + num2
print(num3)
# Output 2 ?
def test_basic():
print(Hello, world)
test_basic()
# Output 3 ?4. พื้นฐาน HTML เบื้องต้น
HTML (Hyper Text Markup Language) คือ ภาษาที่ใช้สำหรับแสดงผลหน้าเว็บไซต์ ก่อนที่จะทำ web scraping ได้อย่างไม่ติดขัดนั้น ความรู้เกี่ยวกับ HTML เบื้องต้นก็มีความจำเป็น หลายคนที่ไม่เคยสัมผัสกับภาษา HTML มาก่อน อาจจะมีความรู้สึกว่าจะอ่านหรือเรียนตามบทความนี้รู้เรื่องไหม คำตอบคือ ไม่น่าจะมีปัญหามากเท่าไหร่ เพราะภาษา HTML เป็นภาษาที่ง่ายกว่าไพธอนค่อนข้างเยอะ และแน่นอนว่าเราไม่จำเป็นต้องรู้ทั้งหมด รู้เพียงแค่บางส่วน มองภาพรวมออกก็ถือว่าโอเครแล้ว ดังนั้นจึงขออธิบาย HTML Tags ต่าง ๆ ในเบื้องต้นที่ควรรู้กันครับ จะเน้นให้มองภาพรวมออก ให้ไปศึกษาเพิ่มเติม
ตัวอย่างไฟล์และ syntax ของ HTML เบื้องต้น ที่มีชื่อว่า index.html โดยสามารถสร้างไฟล์ในโปรเจคท์ได้ตามปกติเหมือนที่สร้าง Python File เพียงแต่เปลี่ยนมาเป็น HTML File
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Web Scraping with Python</title>
</head>
<body>
<div>
<h1>h1 is the biggest heading tag</h1>
<p>This is a paragraph tag</p>
</div>
</body>
</html>คลิ๊กรันใน PyCharm ได้ทันทีที่สัญลักษณ์ Web Browser โดยสามารถเลือกรันในแต่ละเว็บบราวเซอร์ได้ตามต้องการ ซึ่งมีทั้ง Google Chorme, Mozilla Firefox, Safari, Opera, Internet Explorer, Microsoft Edge
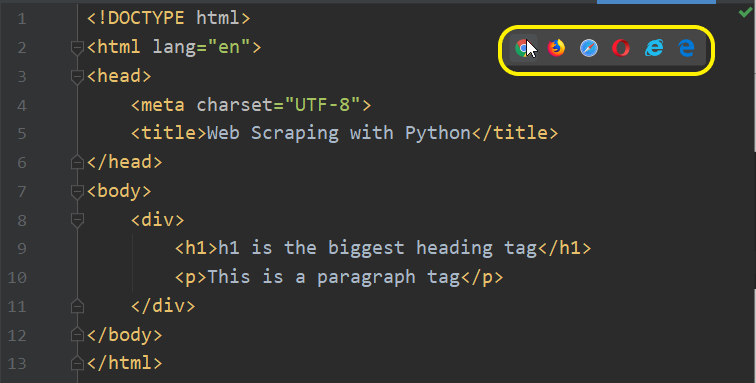
Output
ถ้ายังไม่ได้ติดตั้ง PyCharm สามารถเข้าไปดาวน์โหลดได้ที่หน้าเว็บ PyCharm Community หรือสามารถดูวิดีโอการติดตั้งได้ในคลิป ติดตั้ง PyCharm เพื่อเขียนไพธอน
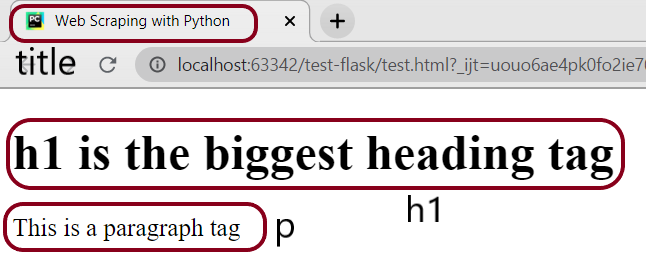
Output
ซึ่งส่วนหลัก ๆ ก็จะประกอบไปด้วย tags
ต่าง ๆ ที่สำคัญดังนี้
<!DOCTYPE html> --> คือ HTML5 (HTML เวอร์ชันล่าสุด)
<html> --> คือ แท็กที่เป็น Root ของหน้าเว็บเพจ
<head> --> คือ แท็กที่ครอบ meta tags ต่าง ๆ ไว้ เช่น title, description, encoding, etc
<title> --> คือ meta title ที่แสดงอยู่บนสุดของหน้าเว็บเพจ
<body> --> คือ ส่วนของเนิ้อหาของหน้าเว็บ เนื้อหา (Content) ทั้งหมดจะถูกเขียนอยู่ภายใต้แท็กนี้
<h1> --> คือ แท็กหัวเรื่อง (Heading) โดยแท็กนี้จะใหญ่สุดในบรรดา heading tags ทุกตัว (h1 - h6) ไล่เรียงกันไป
<p> --> คือ แท็กพารากราฟ เป็นแท็กที่ใช้สำหรับแสดงเนื้อหาข้อความปกติ ซึ่งส่วนใหญ่เนื้อหาของหน้าเว็บ เช่น บล็อก บทความต่าง ๆ จะถูกเขียนในแท็กนี้
ศึกษาเพิ่มเติม HTML Introduction - w3school
ไลบรารียอดนิยมของไพธอนสำหรับงาน web
scraping
ไพธอนมีไลบรารียอดนิยมอยู่หลายตัวที่ใช้สำหรับทำ
web
scraping ไม่ว่าจะเป็น beautifulsoup, scrapy, selenium, etc
ทั้งนี้การเลือกใช้ไลบรารีแต่ละตัวก็ขึ้นอยู่กับว่างานที่กำลังทำมีระดับความยากง่ายแตกต่างกันอย่างไร
โดยแนะนำโปรเจคท์เล็ก ๆ การดึงแบบไม่ยุ่งยากซับซ้อน แนะนำให้ใช้ beautifulsoup
เพราะว่ามีความเรียบง่าย
เขียนโค้ดเพียงไม่กี่บรรทัดก็สามารถดึงข้อมูลได้แล้ว ถ้าเป็นระดับการดึงหรือ scrape
ข้อมูลที่มีความซับซ้อนมากขึ้น
ตัวเลือกที่น่าจะเหมาะสมที่สุดก็คงเป็น scrapy ครับ เพราะ scrapy
คือ เฟรมเวิร์คย่อม ๆ ในการทำ web scraping ดี
ๆ นี่เอง
เริ่มทำ web scraping
เมื่อเราได้รู้จักภาพรวมของการทำ web
scraping กันไปแล้ว ก็มาถึงขั้นตอนการลงมือปฏิบัติกันแล้วครับ
แน่นอนว่าในบทความนี้เราจะใช้ตัวหนึ่งในไลบรารี่ที่ง่ายและสะดวกที่สุดในการทำ web
scraping นั่นก็คือ BeautifulSoup ครับ
โดยเป็นหนึ่งในคลาสที่อยู่ในโมดูล bs4
โดยแนวคิดในการทำ web scraping มีดังต่อไปนี้
- เขียนโค้ดเพื่อทำการ
request ไปที่ URL ของเว็บไซต์หรือหน้าเว็บเพจที่ต้องการ scrape ข้อมูล Client
ทำการ request ไปที่ Server ปลายทาง
- Server ตอบกลับข้อมูลต่าง ๆ มาในหน้าเว็บเพจ โดยไฟล์ต่าง ๆ ที่ถูก render ออกมาจากฝัง server ไม่ว่าจะเป็น HTML, CSS,
JavaScript หรือรูปภาพหรือมีเดียต่าง ๆ
- เมื่อได้ข้อมูลทั้งหมดที่เป็น
HTML เรียบร้อย
ทำการเลือกข้อมูลที่ต้องการในหน้าเว็บ ผ่านการ inspect ดูบนเว็บบราวเซอร์
- เลือก tag ที่ข้อมูลนั้นถูกเก็บอยู่
จากนั้นทำการ extract (สกัด, ดึง)
ข้อมูลออกมา
- ทำการคลีนข้อมูล
(Cleaning Data) เพื่อให้ได้ข้อมูลที่นำไปใช้ได้
- เก็บไว้ในฟอร์แมตหรือในชุดข้อมูลที่มีโครงสร้างชัดเจน (Structured Data) เป็นข้อมูลสุดท้ายที่พร้อมใช้งาน
ซึ่งด้านบนก็คือขั้นตอนหรือแนวคิดในการทำ Web Scraping ในบทความนี้ เมื่อเข้าใจคอนเซ็ปต์เรียบร้อย มองภาพรวมออกชัดเจน
ก็ถึงเวลาที่จะมาเขียนโค้ดกันแล้ว
1. ติดตั้งและใช้งาน requests
ทำการเลือกเครื่องมือเพื่อใช้จับปลา
Requests คือ Python library ที่เอาไว้ใช้สำหรับจัดการเกี่ยวกับการ request ข้อมูลจากหน้าเว็บหรือเว็บบราวเซอร์ โดยไลบรารีตัวนี้แทบจะเรียกได้ว่าเป็นหนึ่งในไลบรารีที่ได้รับความนิยมสูงสุดในภาษาไพธอนกันเลยครับ โดยอ้างอิงจาก pypi.org สถิติการดาวน์โหลดกว่า 14 ล้านครั้งต่อสัปดาห์ และจำนวน Stars ใน GitHub ก็ปาเข้าไปแล้ว 44.1 k เข้าไปแล้ว (สถิติล่าสุดในวันจันทร์ที่ 7 ธันวาคม 2563) ซึ่งในการทำ web scraping นั้น ก็มีความจำเป็นที่จะต้องเรียกใช้งานไลบรารีตัวนี้ เรียกได้ว่า requests แทบจะเป็นอีกหนึ่งพระเอก ที่มีความสำคัญในการทำ web scraping จะเห็นได้ว่า ส่วนใหญ่จะมีการนำไลบรารีตัวนี้เข้าไปเอี่ยวหรือเกี่ยวข้องกับการ scrape ข้อมูลหลาย ๆ งานครับ โดยการติดตั้ง requests ก็ทำได้ปกติทั่วไป
pip install requests2. ติดตั้งและใช้งาน beautifulsoup
BeautifulSoup คือ Python Module ที่ใช้สำหรับการดึงข้อมูลออกมาจาก HTML และ XML หรืออีกทางหนึ่งที่มักเรียกกันก็คือการสกัด (Extract) ข้อมูลออกมา
โดยแรงบันดาลใจในการตั้งชื่อไลบรารีของผู้สร้างนั้นไม่อาจทราบได้ว่าทำไมใช้ชื่อนี้
ซึ่งถ้าแปลตามตัวเลยก็คือ “ซุปสวยงาม”
ถ้าหากถามถึงไลบรารีของไพธอนที่ใช้สำหรับงาน web scraping นั้น beautifulsoup นั้น มันจะเป็นตัวเลือกแรก ๆ ด้วยความนิยมและความง่ายนั่นเอง
ทำการติดตั้ง beautifulsoup4
pip install beautifulsoup43. อิมพอร์ตไลบรารีเข้ามาใช้งานและกำหนด URL
ทำการเลือกเครื่องมือเข้ามาเพื่อใช้จับปลา
หลังจากติดตั้งทั้ง requests และ beautifulsoup เสร็จแล้ว ให้ทำการอิมพอร์ตเข้ามาใช้งาน
from bs4 import BeautifulSoup
import requests
เลือกเครื่องมือจับปลาเข้ามาพร้อมใช้ (photo: canva)
จากนั้นกำหนด url ที่ต้องการโดยเก็บค่าไว้ในตัวแปร url ซึ่งวิธีการนี้เราสามารถนำตัวแปร url ไปใช้ได้ทั่วทั้งโปรเจคท์ของเรา เผื่อในอนาคตได้นำไปใช้ต่อไป ซึ่งถ้าต้องการเปลี่ยนลิ้งค์ก็แก้เพียงแค่ตรงนี้ ไม่ต้อง hardcode แก้เข้าไปทุกที่
url = "https://stackpython.co/courses"ทำการดึงข้อมูลของ url โดยทำการ parse ตัว url เข้าไปใน ฟังก์ชัน requests.get( ) โดยใช้เมธอด get คือใช้ดึงข้อมูล โดยที่ resource ต้นทางไม่มีการเปลี่ยนแปลงของข้อมูล เสร็จแล้วทำการแสดงผลออกทางหน้าจอ โดยใช้ฟังก์ชัน print( ) ตามปกติ
res = requests.get(url)
res.encoding = "utf-8"
print(res)โค้ดทั้งหมดในส่วนแรก
from bs4 import BeautifulSoup
import requests
url = "https://stackpython.co/courses"
res = requests.get(url)
res.encoding = "utf-8"
print(res)Output
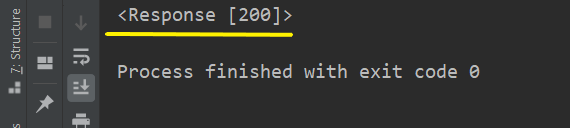
request สำเร็จ ไม่มีปัญหา
จะได้ output ก็คือ HTTP Status Code ในที่นี้คือ 200 แสดงว่าการ request นั้นสำเร็จ โดยขออธิบาย status codes ต่าง ๆ ที่ควรทราบเบื้องต้นดังนี้
- 200 --> OK : การ request สำเร็จ (Success)
- 301 --> Move Permanently: มีการ Redirect จาก URL เดิมไปที่ URL ใหม่
- 404 --> Not Found: ไม่มีหน้าเว็บหรือ URL นี้อยู่ (Page not found)
- 500 --> Internal Server Error: การข้อผิดพลาดจาก Server ภายใน
ซึ่งนอกเหนือจากนี้ ก็มีวิธีการสังเกตในเบื้องต้นแบบง่าย ๆ ว่า HTTP Status Code ที่เห็นอยู่ในหมวดไหน ซึ่งสามารถสังเกตได้จากเลขตัวหน้าสุด
- 2 --> Successful Status
- 3 --> Redirection Status
- 4 --> Client Error Status
- 5 --> Server Error Status
ศึกษา status code เพิ่มเติม
ซึ่งเราสามารถที่จะนำ status code มาทำการกำหนดเงื่อนไขได้
if res.status_code == 200:
print("Successful")
elif res.status_code == 404:
print("Error 404 page not found")
else:
print("Not both 200 and 404")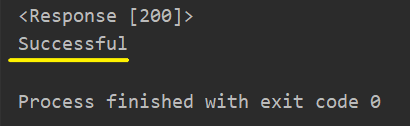
request สำเร็จ ไม่มีปัญหา
4. สร้างตัวแปรเพื่อเก็บ object ของ BeautifulSoup
ขั้นตอนการลากอวนหรือหว่านแหหาปลา
ทำการสร้างตัวแปรเพื่อทำการเก็บ object ของ BeautifulSoup
# soup = BeautifulSoup(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
print(soup)จะได้ข้อมูลของหน้าเว็บเพจออกมาทั้งหมด
Output (Before)
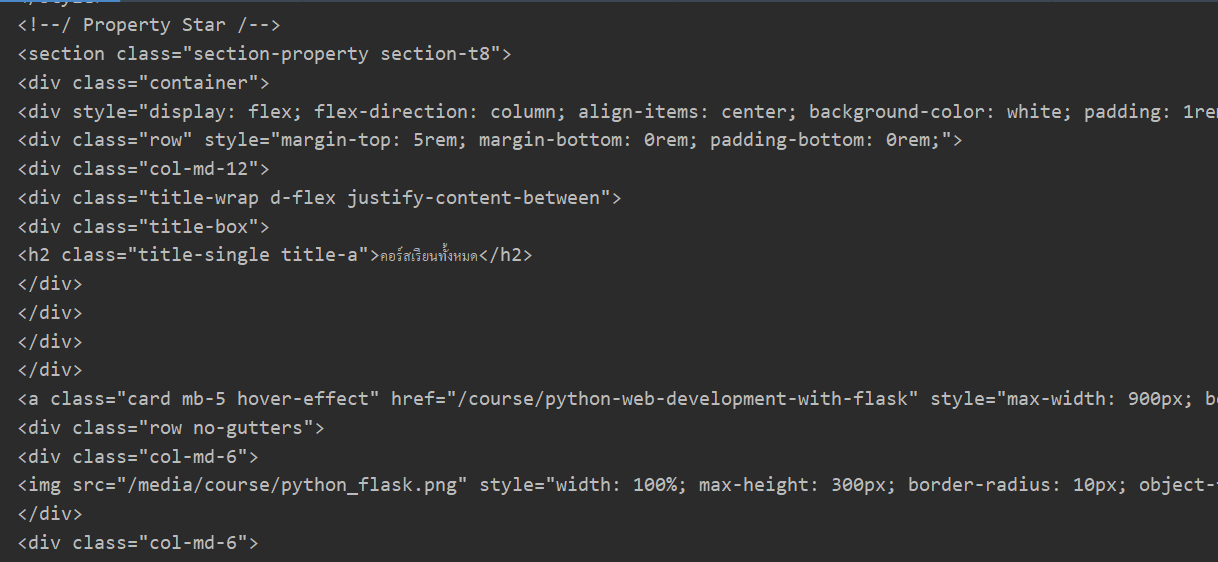
ได้ข้อมูลในหน้าเว็บออกมาทั้งหมด
ข้อมูล HTML ที่ได้แสดงออกมาทั้งหมดและค่อนข้างที่จะดูยาก ดังนั้นมีคำสั่งที่ช่วยจัดฟอร์แมตของแท็กเหล่านี้ให้เป็นระเบียบเรียบร้อย ดูง่าย
# ทำให้ข้อมูลเป็นระเบียบ ดูง่าย ด้วยคำสั่ง prettify()
print(soup.prettify())Output (After)
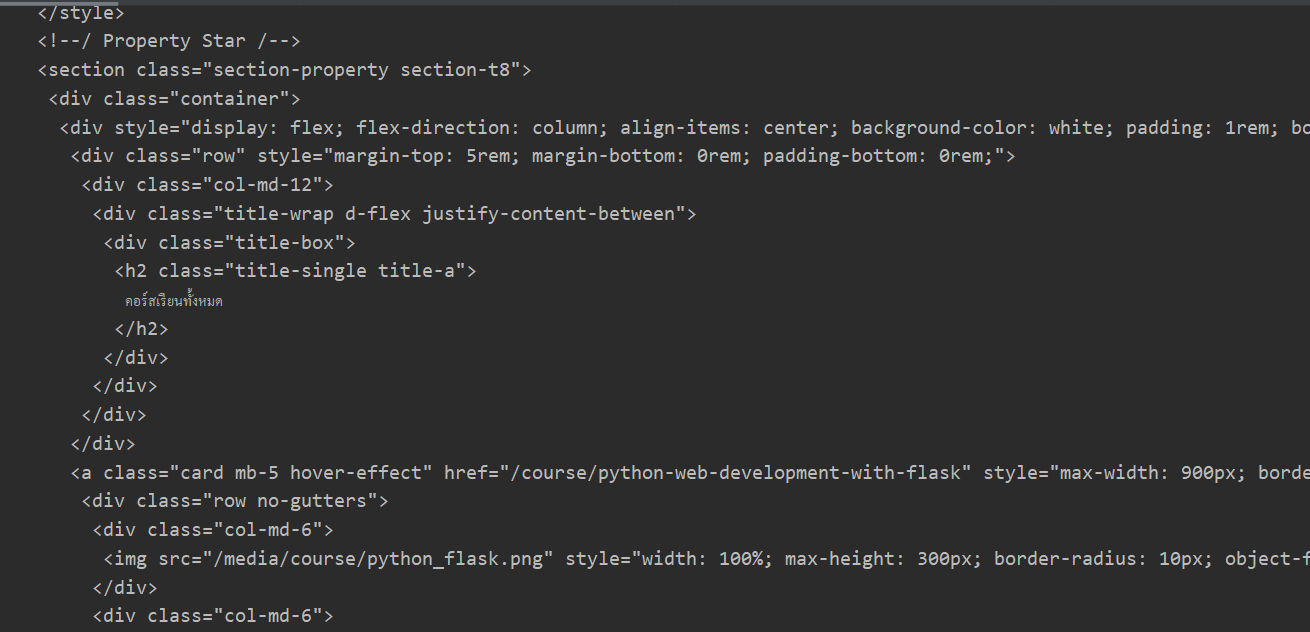
ได้รูปแบบ HTML ที่เป็นระเบียบ ดูง่าย
Note: ถ้าไม่ใส่ 'html.parse' จะได้คำเตือนใน terminal ของ IDE ตามด้านล่าง
GuessedAtParserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("html.parser"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 19 of the file C:/Users/User/PycharmProjects/test-flask/new_scrape.py. To get rid of this warning, pass the additional
ในขั้นตอนนี้จะเห็นว่าเราได้ทำการดึงข้อมูลมาในหน้าเว็บทั้งหมด ซึ่งเราจะได้ทั้งแท็กและคลาสต่าง ๆ ติดมาผสมปนเปเข้ามากับข้อมูลที่เราต้องการ ซึ่งก็เปรียบเสมือนภาพด้านล่าง ซึ่งถ้าหากข้อมูล ของเราคือ ปลา เราก็ต้องมาทำการคัดเลือกปลาต่อไป

ได้กุ้ง หอย ปู ปลา มาแล้วมากมาย แต่ยังไม่ได้เลือกเอาปลาออกมา (photo: canva)
5. การเข้าถึงข้อมูลใน HTML tags ต่าง ๆ
การเข้าถึงข้อมูลในแท็กต่าง ๆ นั้นมีคำสั่งที่สามารถเข้าถึงได้สะดวกรวดเร็ว ไม่ว่าจะเป็น tag ต่าง ๆ เช่น title, h1, p, header, a, etc ตามด้านล่างนี้ โดยทำการสร้างไฟล์ HTML แบบง่าย ๆ ขึ้นมา 1 ไฟล์ ชื่อว่า example.html เพื่อทดสอบ
example.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Web Scraping Tutorial</title>
</head>
<body>
<div>
<h1>Heading tag</h1>
<p>Paragraph tag</p>
</div>
</body>
</html># เข้าถึงข้อมูลในแท็ก title
soup.titleOutput
<title>Web Scraping Tutorial</title># เข้าถึงข้อมูลในแท็ก h1
soup.h1Output
<h1>Heading tag</h1># เข้าถึงข้อมูลในแท็ก p
soup.p
# เข้าถึงข้อมูลในแท็ก p
soup.pOutput
<p>Paragraph tag</p>
การเข้าถึงข้อมูลในแท็กตามตัวอย่างด้านบนจะเห็นว่า จะได้ HTML tags ติดมากับข้อมูลที่ต้องการด้วย ดังนั้นจึงจำเป็นต้องลบแท็กออก สามารถทำได้อย่างง่ายดาย โดยใช้คำสั่ง string ต่อท้ายแท็ก
# เข้าถึงข้อมูลในแท็ก title และทำการดึงออกมาเฉพาะข้อมูลที่ไม่ติดแท็ก
soup.title.stringOutput
Web Scraping Tutorialซึ่งการเข้าถึงข้อมูลในแท็กเหล่านี้โดยตรง นับได้ว่าเป็นวิธีที่ค่อนข้างง่าย สะดวกรวดเร็ว แต่ในทำนองเดียวกันก็มีข้อจำกัด คือสามารถเข้าถึงข้อมูลลำดับแรกของแท็กนี้เท่านั้น แน่นอนว่าในแต่ละเว็บเพจไม่ได้มีแท็กเหล่านี้เพียงแค่แท็กเดียว ถ้าหากเราต้องการเข้าถึงข้อมูลที่ซับซ้อนมากขึ้นและค้นหาทั้งหมด ก็จะมีเมธอดหรืออีกคำสั่งหนึ่งให้ใช้ก็คือ find_all( )
# ค้นหาข้อมูลทั้งหมดที่อยู่ในแท็ก a
soup.find_all('a')6. Extracting and Cleaning data
ขั้นตอนเลือกเอาปลาที่ต้องการ
เมื่อทำการ scrape ข้อมูลมาจากหน้าเว็บเพจเรียบร้อยแล้ว แต่ก็ยังไม่เพียงพอที่จะนำข้อมูลนั้นไปใช้ครับ ดังนั้นจึงต้องมีขึ้นตอนที่เรียกว่า การทำความสะอาดข้อมูล (Cleaning Data) นั่นเองครับ เพื่อให้ข้อมูลอยู่ในฟอร์แมตที่พร้อมใช้งานต่อไป
ลิ้งค์เป้าหมาย: Python Courses - คอร์สเรียนไพธอน
Google Dev Tools
เราสามารถเรียกดูแท็กต่าง ๆ ได้ผ่านหน้าเว็บเพจโดยผ่านเครื่องมือตัวหนึ่งที่มีชื่อว่า "Google Dev Tools" สามารถใช้งานโดยทำการ คลิ๊กขวา ที่หน้าเว็บเพจ --> Inspect
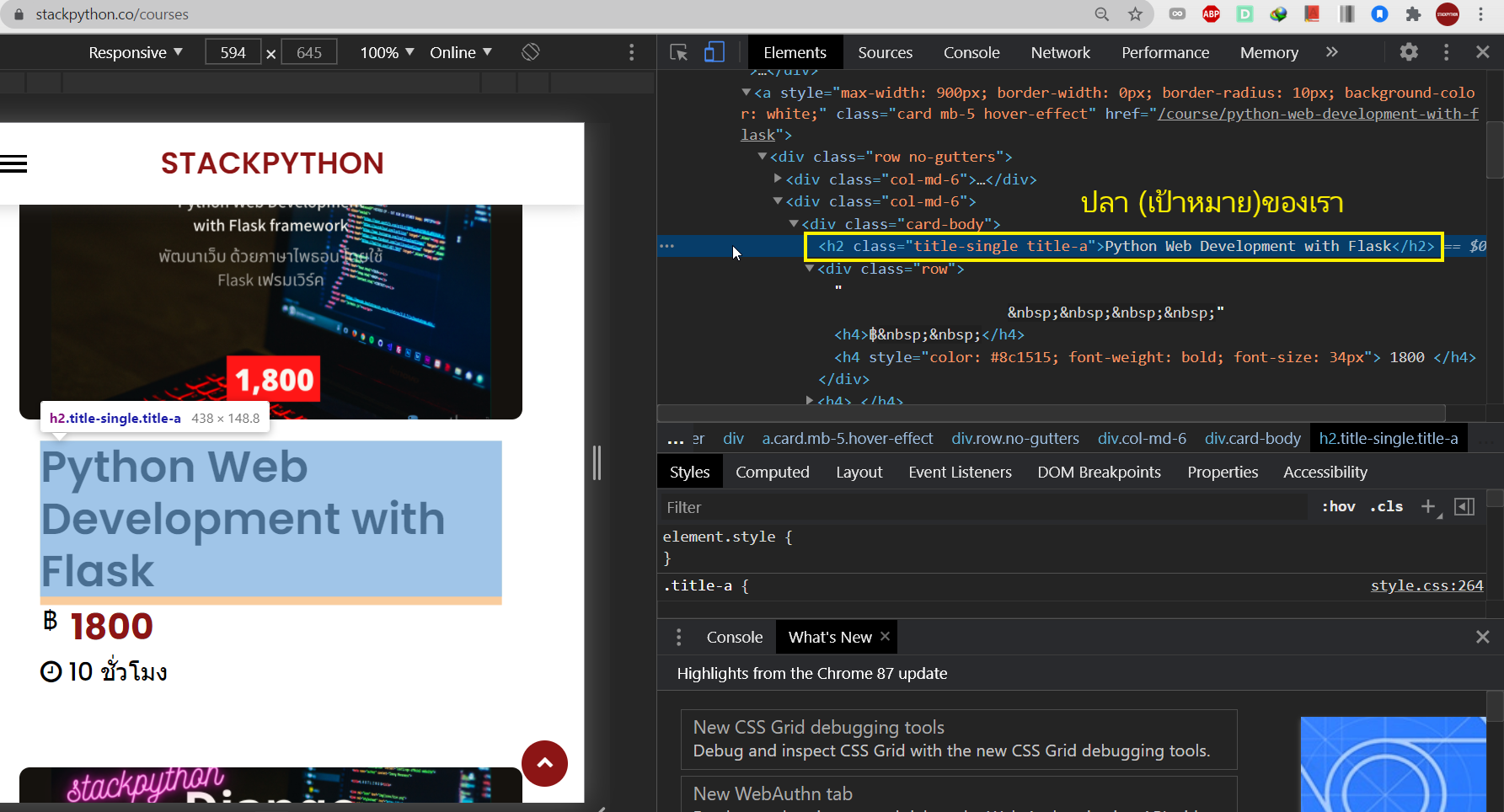
Google Dev Tools เพื่อหาแท็ก
ปลา (เป้าหมายของเรา) จะอยู่ในแท็กนี้
<h2 class="title-single title-a>Python Web Development with Flask</h2>
เมื่อทราบเรียบร้อยว่าข้อมูลที่ต้องการอยู่ในแท็กอะไร ซึ่งในหน้าเว็บนี้ก็คือ "h2" ก็ถึงเวลาที่จะทำการดึงข้อมูลนั้นออกมา
# เข้าถึงรายชื่อของคอร์สโดยผ่านแท็ก h2
courses = soup.find_all('h2')จะได้ออปเจคท์ซึ่งจะเป็นฟอร์แมตในรูปแบบของ List
[<h2 class="title-single title-a">คอร์สเรียนทั้งหมด</h2>, <h2 class="title-single title-a">Python Web Development with Flask</h2>, <h2 class="title-single title-a">Python Web Development with Django</h2>, <h2 class="title-single title-a">Introduction to Python Programming</h2>, <h2 class="title-single title-a">Basic Machine Learning with Python</h2>, <h2 class="title-single title-a">Buy 2 get 2 Course</h2>, <h2 class="title-single title-a">Full Stack Vue.js with Flask (REST Api)</h2>, <h2 class="title-single title-a">All in one Course (5 in 1)</h2>, <h2 class="title-single title-a">Django Wagtail CMS</h2>]
ทำการลูปข้อมูลที่อยู่ในลิสต์ออกมา พร้อมทั้งเก็บเข้าไปในตัวแปรลิสต์ที่ว่างเปล่า จะได้ final object หรือชุดข้อมูลสุดท้ายที่ต้องการ
# Create an empty list
course_list = []
for course in courses:
# Create a new variable --> obj to store
# only course name getting rid of unwanted tags
obj = course.string
# Append each course into a course_list variable
course_list.append(obj)# ปริ้นซ์ข้อมูลในออปเจคท์ออกมาดู
print(course_list)Output
['คอร์สเรียนทั้งหมด', 'Python Web Development with Flask', 'Python Web Development with Django', 'Introduction to Python Programming', 'Basic Machine Learning with Python', 'Buy 2 get 2 Course', 'Full Stack Vue.js with Flask (REST Api)', 'All in one Course (5 in 1)', 'Django Wagtail CMS']

7. บันทึกไฟล์เป็น CSV format
ขั้นตอนเก็บปลาใส่ในภาชนะที่ต้องการ
หลังจากที่เราได้ทำการ scrape และ clean ข้อมูลจนได้ข้อมูลที่ต้องการแล้วเรียบร้อย ขั้นตอนสุดท้ายก็คือการบันทึกข้อมูลเก็บไว้ใช้งานต่อไป โดยในบทความนี้จะทำการบันทึกในรูปแบบของ CSV ไฟล์ ซึ่งเป็นหนึ่งในฟอร์แมตที่ได้รับความนิยมอย่างสูง และใน Python มี Built-in Library ที่มีชื่อว่า csv ให้สามารถเรียกใช้งานเกี่ยวกับการจัดการ CSV ไฟล์ต่าง ๆ โดยอิมพอร์ตเข้ามาใช้งานได้เลย
import requests
from bs4 import BeautifulSoup
import csv # Newจากนั้นทำการสร้างตัวแปรที่มีชื่อว่า csv_col โดยในตัวแปรนี้จะทำการเก็บข้อมูลในรูปแบบ Nested List (ลิสต์ซ้อนลิสต์) โดย
- 'title' index 0 (ตำแหน่งแรก) จะเป็น ชื่อคอลัมน์ ที่เรากำหนดขึ้นมาเอง
- course_list index 1 (ตำแหน่งที่ 2) จะเป็น ข้อมูลที่อยู่ในคอลัมน์ นั้น โดยข้อมูลนี้มาจากออปเจคท์ที่เรา scrape ข้อมูลโดยใช้ beautifulsoup นั่นเอง
# Define row and column (DataFrame)
csv_col = [['title'], [course_list]]
ทำการกำหนดตัวแปร f เพื่อเก็บข้อมูลในฟังก์ชัน open( ) นี่คือ Built-in function ของไพธอน ที่ใช้สำหรับเปิดไฟล์ โดย
- course_titles ชื่อไฟล์ที่ต้องการสร้าง
- w โหมดของไฟล์นี้ โดย w = write คือเขียนไฟล์ ถ้าเป็นอ่านไฟล์จะใช้ r นั่นก็คือ read นั่นเอง
# Name a file, and put w as an argument to tell this is "writer" file
f = open('course_titles.csv', 'w')with f:
writer = csv.writer(f)
for row in csv_col:
writer.writerow(row)โค้ดเขียนไฟล์ CSV
# Define row and column (Dataframe)
col_csv = [['title'], [index_sel_tag]]
# Name a file, and put w as an argument to tell this is "writer" file
f = open('filename.csv', 'w')
with f:
writer = csv.writer(f)
for row in csv_col:
writer.writerow(row)
Requests limitation
การที่เราทำ web scraping นั้น นั่นก็หมายถึงเรากำลังทำการ request ข้อมูลไปที่ server ของเว็บนั้น ๆ แน่นอนว่ามันจะเกิดการ request ไปที่เซิร์ฟเวอร์นั้น ๆ มากจนเกินไป อาจทำให้ IP ของเราโดนบล็อกจากเจ้าของเว็บไซต์ (Website Owner) นั้นได้ ดังนั้นเราก็มีวิธีแก้ปัญหาได้เบื้องต้น เช่น ทำการหน่วงเวลาการ scrape ข้อมูลสัก 10 - 20 วินาที เป็นต้น โดยการหน่วงเวลาหรือ delay นี้ ในไพธอนจะมี built-in library คือ time ซึ่งสามารถอิมพอร์ตเข้ามาใช้ได้ทันที และสามารถเรียกใช้เมธอดที่มีชื่อว่า sleep( ) โดยถ้าอยากหน่วง 10 วินาที ก็สามารถทำได้โดย sleep(10) อันนี้แค่เกริ่นคร่าว ๆ รายละเอียดเพิ่มเติมจะอยู่ใน Part 2
การนำข้อมูลที่ได้จากการทำ web scraping ไปใช้งาน
ขั้นตอนนำปลาไปปรุงอาหาร
หลังจากที่เราได้ทำการ scrape ข้อมูลในหน้า webpage ออกมาและทำการบันทึกข้อมูลในรูปแบบ CSV เรียบร้อย จากนั้นก็ขึ้นอยู่กับว่าจะนำข้อมูลไปทำอะไรต่อไป เช่น นำไปวิเคราะห์ (Data Analysis), นำไปแสดงผลในรูปแบบต่าง ๆ (Data Visualization), นำไปเป็น Dataset เพื่อใช้กับโปรเจคท์ Machine Learning, ฯลฯ เป็นต้น

จะนำไปทำอะไร ก็สุดแล้วแต่ต้องการ ในภาพคือกำลังจะนำไปทำลาบ ;)(photo: canva)
เอาไปทำเกี่ยวกับงาน Data Visualiztion เช่นกราฟต่าง ๆ (Photo: matplotlib.org)
Final Code
scraping.py
from bs4 import BeautifulSoup
import requests
import csv
url = "https://stackpython.co/courses"
res = requests.get(url)
res.encoding = "utf-8"
print(res)
soup = BeautifulSoup(res.text, 'html.parser')
# print(soup)
# print(soup.prettify())
courses = soup.find_all('h2')
print(courses)
# Create an empty list
course_list = []
for course in courses:
# Create new variable --> obj to store
# only course name getting rid of unwanted tags
obj = course.string
# Append each course into a course_list variable
course_list.append(obj)
print(course_list)
# Define row and column (DataFrame)
csv_col = [['title'], [course_list]]
# Name a file, and put w as an argument to tell this is "writer" file
f = open('filename.csv', 'w')
with f:
writer = csv.writer(f)
for row in csv_col:
writer.writerow(row)
# Display type of this object (Of course, it's "list")
print(type(course_list))
# Test accessing position 1 of the list
print(course_list[1])
# To count how many courses in the list
print(len(course_list))สรุป
ข้อสรุปโดยรวมที่ได้หลังจากอ่านบทความนี้จบ
- ควรรู้พื้นฐานภาษาโปรแกรมมิ่งที่เกี่ยวข้องเบื้องต้น เช่น Python และ HTML ก่อนเรียน Web Scraping พร้อมทั้งตั้งเป้าหมาย
- ควรศึกษาข้อกำหนดของเว็บที่ต้องการจะดึงข้อมูลให้มั่นใจเสียก่อน เพื่อที่จะได้ไม่ขัดหรือล่วงละเมิดต่อข้อกำหนดของเว็บนั้น ๆ ทำอย่างไรถึงจะทำ web scraping แล้วจะไม่โดนแบนหรือบล็อกจาก website หรือ web server ปลายทาง
- การทำ Web Scraping นั้นไม่ได้มีอาชีพที่ชื่อว่า web scraping โดยตรง เหมือนกับอาชีพอื่น ๆ เช่น Backend/Frontend Developer, Data Scientist, Machine Learning Engineer, etc แต่ว่าการที่รู้และสามารถทำ Web Scraping ได้ ก็เท่ากับว่าเป็นการเพิ่มสกิลให้กับตัวเอง เผื่อเป็นอีกหนึ่งทักษะที่สามารถนำไปทำมาหากินหรือประยุกต์เข้ากับงานอื่น ๆ ได้
ก็จบลงไปเรียบร้อยกับบทความ Web Scraping โดยการใช้ BeautifulSoup จากทาง STACKPYTHON ผู้เขียนหวังว่า ผู้อ่านทุกท่านที่ได้อ่านบทความนี้จนจบ (ขอขอบคุณสำหรับท่านที่อ่านจนจบ) จะได้ทำความรู้จักและเข้าใจเกี่ยวกับการทำ Web Scraping ในเกือบจะทุก ๆ มิติ และยังได้ทดสอบทำการ Scrape ข้อมูลและทำการบันทึกเก็บลงในฟอร์แมตยอดนิยมอย่าง CSV เพื่อนำไปใช้งานต่อไป ซึ่งนี่เรียกได้ว่าความสำเร็จก้าวแรกกันแล้ว ซึ่งแน่นอนว่า เราจะต้องต่อยอดขึ้นไปในระดับที่สูงและซับซ้อนมากยิ่งขึ้น โดยจะมีการทำเป็นคลิปของซีรียนี้ลงในช่อง YouTube ของเรา ท่านใดที่ยังไม่ได้กด subscribe ก็กดไว้ได้เลยครับ มีเนื้อหาดี ๆ น่าสนใจอยู่หลากหลายเนื้อหาในนั้น
"ถ้ามีคำถามหรือข้อเสนอแนะหรือฟีดแบ็คตรงส่วนไหน สามารถคอมเมนต์เข้ามาที่คอมเมนต์ด้านล่างบทความนี้กันได้เลย ซึ่งสิ่งเหล่านี้มีความหมายต่อการเขียนบทความมาก"
ขอขอบคุณทุกท่านที่อ่านจนจบ พบกันอีกครั้งในบทความถัดไป ขอให้มีความสุขและสนุกในการเรียนรู้ เข้าหน้าหนาวแล้ว รักษาสุขภาพกันด้วยนะครับ
| Like | Comment | Share | >> STACKPYTHON
Reference
กิจกรรมที่กำลังจะมาถึง
ไม่พลาดกิจกรรมเด็ด ๆ ที่น่าสนใจ
Python Bundle 2023 สมัครครั้งเดียวเรียนได้ทุกคอร์ส
Event นี้จะเริ่มขึ้นใน April 25, 2023
รายละเอียดเพิ่มเติม/สมัครเข้าร่วมคำอธิบาย
คอร์สเรียนไพธอนออนไลน์ที่เราได้รวบรวมและได้ย่อยจากประสบการณ์จริงและเพื่อย่นระยะเวลาในการเรียนรู้ ลองผิด ลองถูกด้วยตัวเองมาให้แล้ว เพราะเวลามีค่าเป็นอย่างยิ่ง พร้อมด้วยการซัพพอร์ตอย่างดี