จาก Excel สู่ Pandas จัดการตารางข้อมูลด้วย Python
S T A C K P Y T H O N-
 Natanop Pimonsathian
Natanop Pimonsathian
- Aug. 2, 2021

สวัสดีครับ หลาย ๆ ท่านคงจะคุ้นเคยกับการจัดการตารางข้อมูลด้วยโปรแกรม Microsoft Excel กัน ซึ่งเป็นที่ทราบกันดีว่าโปรแกรมนี้มีฟังก์ชั่นการใช้หลากหลาย และง่ายต่อการใช้งาน แต่เคยสงสัยกันไหมครับว่าประสิทธิภาพของการทำงานกับข้อมูลขนาดใหญ่ที่เราเก็บข้อมูลได้ละเอียดมากขึ้น Excel ยังจะเป็นทางเลือกที่เหมาะสมที่สุดอยู่หรือไม่ จากข้อมูลรายเดือน อาจจะถูกมองย่อยลงมาในระดับรายวัน จากรายวันเป็นรายชั่วโมง ปริมาณข้อมูลก็เพิ่มขึ้นอย่างมาก
วิดีโอแนะนำ( YouTube): Python Pandas - dataframe, CSV, Excel ฉบับใช้งานจริง
อันดับแรก หากข้อมูลของเรามีจำนวนหลักล้านแถว ต้องบอกเลยว่า Excel ไม่มีทางรองรับได้อย่างแน่นอนเพราะขีดจำกัดของโปรแกรมนี้คือ 1,048,576 แถว ดังนั้นเราจำเป็นต้องหาวิธีอื่นเพื่อที่จะมาเปิดไฟล์ลักษณะนี้
ประการต่อมา แม้ว่าข้อมูลของเราจะมีจำนวนน้อยกว่า row limit ของ Excel แต่ในบางครั้งเราจะเจอปัญหาการทำงานที่ช้าเพราะต้องรอคอมพิวเตอร์ประมวลผลให้เรา ยกตัวอย่างเช่น เราต้องการสรุปค่าจากข้อมูลในตาราง เช่น ยอดขายโดยรวม หากใช้โปรแกรม Excel รวบรวมรายการที่มีนับแสนแถวด้วย pivot table ก็อาจจะต้องใช้เวลา อีกกรณีตัวอย่างหนึ่งก็คือ การคำนวนด้วยสูตรหรือฟังก์ชั่นต่าง ๆ ที่ซับซ้อนขึ้นมา จะใช้เวลาค่อนข้างนาน
เรื่องสุดท้ายคือเรื่องของการ update ข้อมูลและการทำงานโดยอัตโนมัติ เป็นที่ทราบกันดีว่า excel มีทางเลือกให้เช่น การ refresh จาก Power Query แต่ก็อาจจะใช้เวลานานในการประมวลผลอีกเช่นกัน ยิ่งไปกว่านั้น หากคุณเป็นที่มีความสนใจเริ่มต้นในด้าน Data analytics / Data science แล้ว ต้องบอกเลยว่าห้ามพลาดเนื้อหาในบล๊อกนี้เด็ดขาด เพราะ Pandas คือประตูสู่การจัดการตารางข้อมูลที่เป็น input สำหรับ prediction models ต่าง ๆ
อะไรคือ Pandas? เหมือนและแตกต่างจาก Python อย่างไร
ผมขออนุญาตใช้โอกาสนี้อธิบายให้ทราบว่า Pandas เป็นหนึ่งใน Libraries ของ Python Programming ซึ่งเวลาที่เราจะใช้งานนั้นจะต้องมีการเรียกขึ้นมาด้วยการ Import module
ส่วนชื่อของ Pandas นั้นจริงๆ มาจากสองที่มา ความหมายแรกนั้นบอกว่า Pandas ย่อมาจาก Python Data Analysis Library อีกความหมายหนึ่งก็คือมาจากคำว่า Panel Data หรือที่แปลว่าตารางข้อมูลนั่นเอง
เมื่อจบบล็อกนี้ คุณจะสามารถ
เรียกใช้งาน Pandas Library ได้อย่างถูกต้อง
อ่านข้อมูล และเปิดไฟล์ Excel /CSV ได้
ตรวจสอบคุณภาพของข้อมูล
เลือกเฉพาะแถวและคอลัมน์ที่ต้องการ
คำนวนค่าต่างๆ
เซฟ และปิดไฟล์
โดยตัวอย่างขอข้อมูลที่เราจะมาเรียนรู้การทำงานผ่าน Pandas กันนั้นคือสถิติยอดขายจาก Walmart โดยสามารถดาวน์โหลดได้จากเว็บไชต์ Kaggle.com ซึ่งเป็นแหล่งเรียนรู้ด้าน Data ยอดนิยม
1. เรียกใช้งาน Pandas Library ได้อย่างถูกต้อง
สำหรับข้อนี้ สิ่งที่เราต้องทำคือการ import pandas library เข้ามาในหน้า environment เพื่อใช้งานฟังก์ชั่นต่างๆ โดยใช้คำสั่ง import pandas as pd คำสั่งนี้ประกอบด้วยสองส่วนคือ ส่วนที่เราบอกว่า import library อะไรเข้ามา และส่วนหลังที่กำหนด alias ของชื่อ library ดังกล่าว
import pandas as pd2. อ่านข้อมูล และเปิดไฟล์ Excel /CSV ได้
เมื่อเรียกใช้งาน Pandas เรียบร้อย เราก็จะมาเปิดไฟล์กัน โดยใช้คำสั่ง read ที่ใส่ชื่อ directory และไฟล์ที่เราต้องการเปิดขึ้นมาเข้าไปจะมีไฟล์สองประเภทที่เราจะเปิดอ่านเป็นประจำ ไฟล์ประเภทแรกคือ .csv หรือ comma separated value ซึ่ง Pandas จะทำการอ่านค่าและแบ่งเป็นแต่ละคอลัมน์และแถวโดยอัตโนมัติ เราจะใช้คำสั่ง pd.read_csv() กัน ตัวอย่างไฟล์ข้อมูลของเราก็คือ Walmart sales data
# read csv file
pd.read_csv('datasets/WALMART_SALES_DATA.csv')
Note: ลิ้งค์สำหรับดาวน์โหลด datasets
นอกจากนี้ เพื่อเรียกข้อมูลขึ้นมาในขั้นตอนต่อไป เราจะกำหนดมันให้เป็นตัวแปรชื่อ walmart
# read csv and assign it as variable
walmart = pd.read_csv('datasets/WALMART_SALES_DATA.csv')
# call this variable
walmart
แล้วถ้าเป็นไฟล์เป็น excel เราก็แค่เปลี่ยนวิธีการอ่านเป็น read_excel() แล้วก็กำหนดหน้า sheet ที่เราต้องการผ่าน input ที่ชื่อว่า sheet_name
# read excel
walmart_excel = pd.read_excel('datasets/WALMART_SALES_DATA.xlsx', sheet_name='Sheet1')
walmart_excel
3. ตรวจสอบคุณภาพของข้อมูล
คุณภาพของข้อมูลสามารถมองได้หลายมุมมอง เช่นความครบถ้วน ความถูกต้องของค่าตัวแปร
เราจะมาเริ่มต้นกับการดูจำนวนแถวและคอลัมน์กันก่อนโดยใช้คำสั่ง df.shape โดยจะส่งค่ากลับมาเป็นจำนวนแถวและคอลัมน์ ตามลำดับ เช่นในกรณีนี้ข้อมูลของเรามี 6435 แถว และ 8 คอลัมน์
# check number of rows and columns
walmart.shape# display top 5 rows
walmart.head()
# display bottom 5 rows
walmart.tail()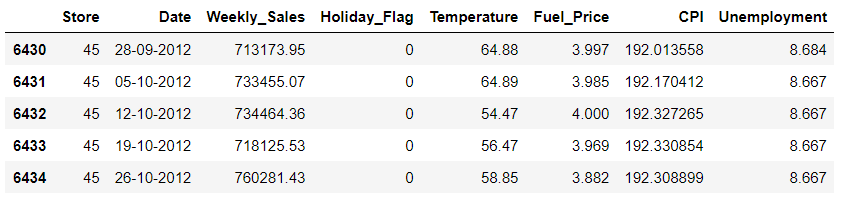
เราพอจะเห็นหน้าตาของข้อมูลแล้ว ต่อไปเราจะสังเกตดูประเภทของตัวแปรโดยใช้คำสั่ง df.info() ซึ่งจะแสดงชื่อคอลัมน์ จำนวนแถวที่มีข้อมูลครับ และประเภทของตัวแปร (เป็นตัวอักขระ ตัวเลข หรือทศนิยม) ตัวอย่างเช่น column Date มีจำนวนครบถ้วนทั้ง 6435 แถวและประเภทตัวแปรคือ object แสดงว่าเป็นตัวอักขระ
# using df.info()
walmart.info()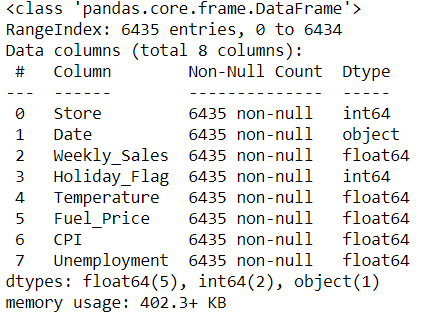
คำถามต่อมา ถ้าหากว่าเราต้องการดูค่าทางสถิติจะต้องทำอย่างไร ในกรณีนี้ pandas ก็มีทางเลือกให้เราใช้ฟังก์ชั่น df.describe() โดยจะให้ค่ากลับมาดังนี้
- count จำนวนข้อมูลที่มี
- mean ค่าเฉลี่ย
- std ส่วนเบี่ยงเบนมาตรฐาน
- min ค่าต่ำที่สุด
- 25%, 50%, 75% percentile ของข้อมูลตั้งแต่ 25 50 และ 75
- max ค่าสูงสุด
# using df.describe
walmart.describe()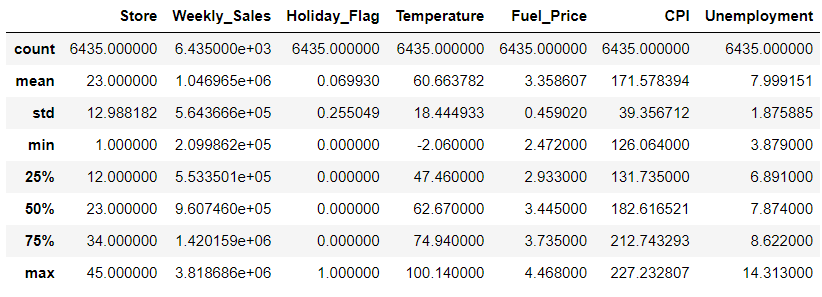
4. เลือกเฉพาะแถวและคอลัมน์ที่ต้องการ
หากเราต้องการดูข้อมูลเฉพาะแถวที่ต้องการ สามารถทำได้ง่ายๆด้วยการเรียกหา index นั้น ๆ โดยใช้คำสั่ง df.iloc โดย index จะเริ่มจากศูนย์เสมอ การใช้คำสั่ง iloc นี้เป็นการบ่งบอกว่าเราจะเรียกข้อมูลที่ต้องการโดยใช้ index ของตารางเป็นตัวอ้างอิง ตัวอย่างแรก เราจะมาลองเรียกแถวที่ 5 ของข้อมูล นั่นเท่ากับว่าเราจะต้องเรียกหาข้อมูลด้วยค่า index = 4# get the 5th row
walmart.iloc[4]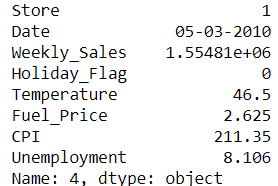
# get top 5 rows
walmart.iloc[0:5]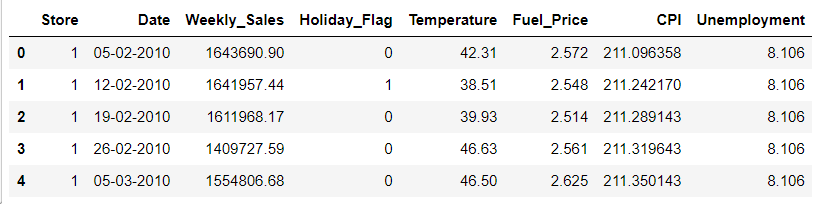
ลำดับต่อไป เราจะลองมาเพิ่มการเรียกเฉพาะคอลัมน์เข้าไป โดยใช้หลักการเดียวกันแต่จะใช้เครื่องหมาย , ในการแบ่งระหว่างการเรียกแถวและคอลัมน์ ตัวอย่างนี้แสดงการเรียก 5 แถวแรกของข้อมูลและ 4 คอลัมน์แรกจากซ้ายมือสุด
# get top 5 rows and 4 left most columns
walmart.iloc[0:5, 0:4]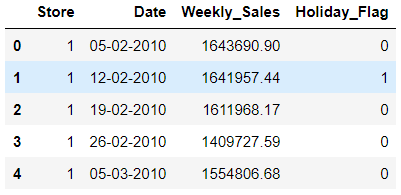
# get top 5 rows and 4 left most columns - using loc operator
walmart.loc[0:4, 'Store':'Holiday_Flag']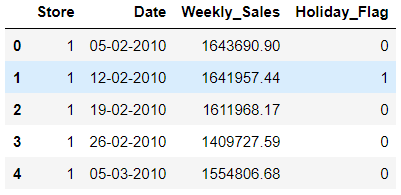
สิ่งที่ควรรู้อีกประการหนึ่งก็คือ เราสามารถที่จะกำหนดให้สื่งที่เราเลือกจากตารางกลายเป็น dataframe ตัวใหม่ได้ด้วยการประกาศตัวแปร
wm_subset = walmart.loc[0:4, 'Store':'Holiday_Flag']
wm_subset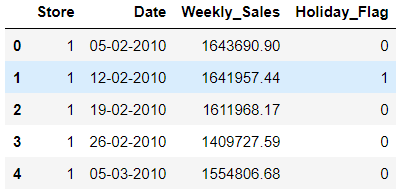
# get columns using .loc
wm_subset = walmart.loc[:, 'Store':'Holiday_Flag']
wm_subset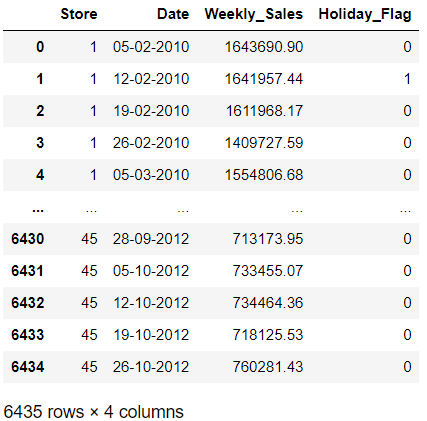
# get columns using dataframe subsetting
wm_subset = walmart[['Store', 'Date', 'Weekly_Sales', 'Holiday_Flag']]
wm_subset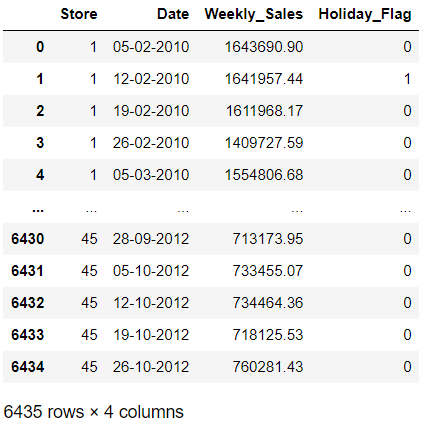
ประเด็นต่อมา คือการเลือกข้อมูลตามเงื่อนไขที่กำหนด เราจะลองกรองข้อมูลดูว่ามีสัปดาห์ไหนของข้อมูลที่มีวันนักขัตฤกษ์ (Holiday flag = 1) ซึ่งสามารถใช้การ filter ได้ตามโค้ดด้านล่างนี้เลย ในลำดับแรก เราจะเห็นเมื่อเราสร้างเงื่อนไขขึ้นมา คอมพิวเตอร์จะทำการเช็คไปทีละแถวแล้วแสดว่าเงื่อนไขนั้นเป็นจริงหรือไม่ หากเป็นจริง ก็จะแสดงค่าออกมาเป็น True
# filter Holiday_Flag = 1
wm_subset['Holiday_Flag']==1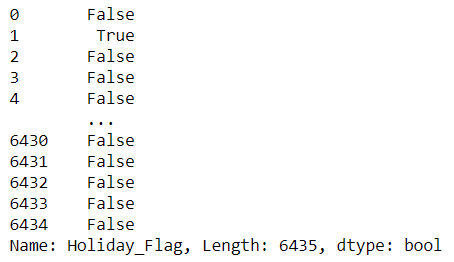
# using filter Holiday_Flag = 1
walmart_holiday = wm_subset[wm_subset['Holiday_Flag']==1]
walmart_holiday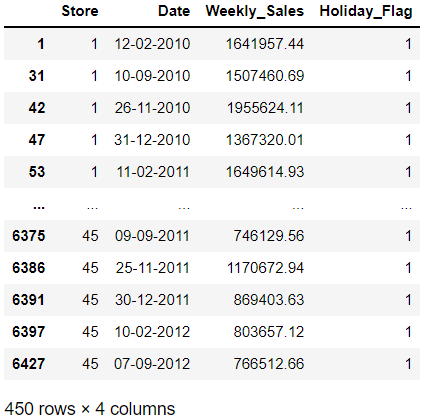
5. การคำนวนค่าต่างๆ
เราจะมาลองแก้ไขเพิ่มเติมค่าของแต่ละคอลัมน์จากข้อมูลที่เรากรองมา โดยตัวอย่างคือการแปลง Weekly sales ให้กลายเป็นหลักล้าน ด้วยการหาร 100000 ซึ่งเราสามารถทำได้ดังนี้ ขั้นตอนแรก ลองมาคำนวนค่ากันโดยหยิบคอลัมน์ Weekly_Sales ออกมา# Weekly sales recalculation
walmart_holiday['Weekly_Sales']/1000000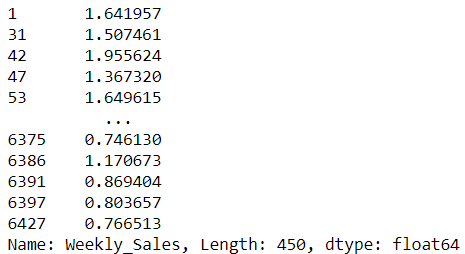
ขั้นตอนที่สอง เราจะกำหนดให้สิ่งที่คำนวนออกมาเป็นค่าของคอลัมน์ Unemployment ใหม่ บางท่านอาจจะเจอกับ Warning ที่ชื่อว่า SettingWithCopyWarning ซึ่งเราจะได้พูดคุยกันในโอกาสต่อไป
# Weekly sales recalculation recalculation and assign to the current column
walmart_holiday['Weekly_Sales'] = walmart_holiday['Weekly_Sales']/1000000
การเซฟและปิดไฟล์
นี่คือขั้นตอนที่สำคัญหากเราต้องการจะนำข้อมูลไปใช้งานต่อกับโปรแกรมภายนอก เราจะใช้คำสั่ง df.to_csv() หรือ df.to_excel() ในการส่งไฟล์ออกไปจาก environment ของเรา ให้รันโค้ดด้านล่างนี้ แล้วไปสังเกตใน folder datasets กัน จะเห็นว่าหากเปิด file excel ขึ้นมาจะมีคอลัมน์ index แถมมาด้วย ซึ่งเราสามารถเลือกที่ไม่ใส่ได้ด้วยการเชทค่า index=False# save as csv
walmart_holiday.to_csv('datasets/out_walmart.csv', index=False)
# save as excel
walmart_holiday.to_excel('datasets/out_walmart.xlsx')เป็นอย่างไรกับบ้างครับกับการเรียนรู้แบบรวดเร็วกับ Pandas อันที่จริงแล้วผมจะบอกเราสามารถเขียนทุกอย่างรวมกันได้แบบนี้ซึ่งเป็นจุดเริ่มต้นของการ automate กระบวนการทำงานกับข้อมูล
# import pandas
import pandas as pd
# read data
walmart = pd.read_csv('datasets/WALMART_SALES_DATA.csv')
# get some columns only
wm_subset = walmart[['Store', 'Date', 'Weekly_Sales', 'Holiday_Flag']]
# filter to get holiday = 1 only
walmart_holiday = wm_subset[wm_subset['Holiday_Flag']==1]
# Weekly sales recalculation recalculation and assign to the current column
walmart_holiday['Weekly_Sales'] = walmart_holiday['Weekly_Sales']/1000000
# save as csv
walmart_holiday.to_csv('datasets/out_walmart.csv', index=False)
# display the top 5 rows
walmart_holiday.head()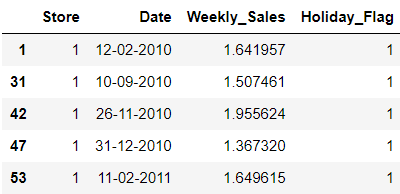
กิจกรรมที่กำลังจะมาถึง
ไม่พลาดกิจกรรมเด็ด ๆ ที่น่าสนใจ
Python Bundle 2023 สมัครครั้งเดียวเรียนได้ทุกคอร์ส
Event นี้จะเริ่มขึ้นใน April 25, 2023
รายละเอียดเพิ่มเติม/สมัครเข้าร่วมคำอธิบาย
คอร์สเรียนไพธอนออนไลน์ที่เราได้รวบรวมและได้ย่อยจากประสบการณ์จริงและเพื่อย่นระยะเวลาในการเรียนรู้ ลองผิด ลองถูกด้วยตัวเองมาให้แล้ว เพราะเวลามีค่าเป็นอย่างยิ่ง พร้อมด้วยการซัพพอร์ตอย่างดี