จัดการไฟล์ csv อย่างไวด้วย Python pandas read_csv
S T A C K P Y T H O N-
 Natanop Pimonsathian
Natanop Pimonsathian
- Sept. 12, 2021

อ่านและเตรียมไฟล์ข้อมูลได้ด้วยโค้ดไม่กี่บรรทัด หนึ่งในเทคนิคที่ผู้ใช้งาน pandas ควรรู้เพื่อลดเวลาในการรันโปรแกรม ซึ่งในบทความนี้สามารถลดได้ถึง 6 เท่า
Table of Contents
- Introduction
- Data Exploration
- Build Sample Script for Data Processing
- Build a Script for Performance Measurement
- Results and Conclusion Remarks
1. Introduction
ไม่ว่าการวิเคราะห์ข้อมูลจะมีกระบวนการที่ซับซ้อนแค่ไหนใน Pandas Library ของ Python สิ่งที่ต้องทำเสมอคือการนำเข้าไฟล์ข้อมูล แต่เคยทราบกันหรือไม่ว่าเราสามารถลดขั้นตอนการทำงาน หรือลดจำนวนบรรทัดของโค้ดเรา ได้ด้วยการกำหนดค่า input ต่างๆ ในฟังก์ชั่น read_csv() โดยในวันนี้เราจะมาทดลอง processing data เปลี่ยนค่าในคอลัมน์ ตัดแถว และเลือกคอลัมน์ด้วยสองวิธีการหลักใน pandas
ใช้คำสั่ง pd.read_csv() อ่านไฟล์ทั้งหมดและมาทำกระบวนการต่างๆ ทีหลัง โดยจะเรียกวิธีนี้ว่า read-then-process method
ใช้คำสั่ง pd.read_csv() อ่านไฟล์และทำกระบวนการทั้งหมดในทีเดียว โดยจะเรียกวิธีนี้ว่า read-and-process method
เราจะเน้นเรื่องความสะดวกในการเขียนโค้ดเป็นหลัก โดยเฉพาะในเรื่องของ conciseness แต่ทั้งนี้เพื่อเป็นการคลายข้อสงสัยในมิติด้านประสิทธิภาพหรือ performance เราจะทำการเปรียบเทียบในเรื่องของระยะเวลาในการทำงานของโปรแกรม ขนาดของไฟล์ และความยาวของ code ที่เราต้องเขียน เราจะใช้ข้อมูลตัวอย่าง sales transaction ขนาด 1.5 ล้านบรรทัด
โดยขั้นตอนในการทดลองมีดังนี้
สร้าง python script สำหรับทั้งสองวิธี
อ่านไฟล์
Run script วัดค่าประสิทธิภาพในด้านต่างๆ โดย restart runtime เมื่อเปลี่ยนวิธี
สำหรับ technical settings มีดังนี้
Python 3.8.5 on Anaconda
Hardware
CPU: AMD Ryzen 7 4800H 2.90 GHz
GPU: AMD RADEON RX5500M 4 GB GDDR6
RAM: 16GB DDR4 3200MHz
2. Data Exploration
เมื่อ ทราบ conditions ต่างๆ ของการทดลองแล้ว เราจะไปเริ่มต้นกันที่การเขียนโค้ดก่อนโดยเริ่มต้นจากการทำ data exploration ใช้ jupyter notebook เป็น IDE ของเราเพื่อดูหน้าตาไฟล์
ขั้นแรก เราจะโหลดทั้งไฟล์ข้อมูลเข้ามาด้วยคำสั่ง pd.read_csv()
import pandas as pd
df = pd.read_csv('dataset/1500000SalesRecords.csv')จากนั้นเราจะใช้คำสั่ง df.shape เพื่อดูจำนวนแถวและคอลัมน์ ซึ่งจะพบว่าข้อมูลนี้มีทั้งหมด 1.5 ล้านแถว และ 14 คอลัมน์
print(df.shape)Output
(1500000, 14)
สิ่งต่อไปที่ควรทำคือการดูหน้าตาของข้อมูลด้วยการใช้คำสั่ง df.head() โดยจะเรียกมาแค่ 3 แถวแรกเท่านั้น
df.head(3)output:

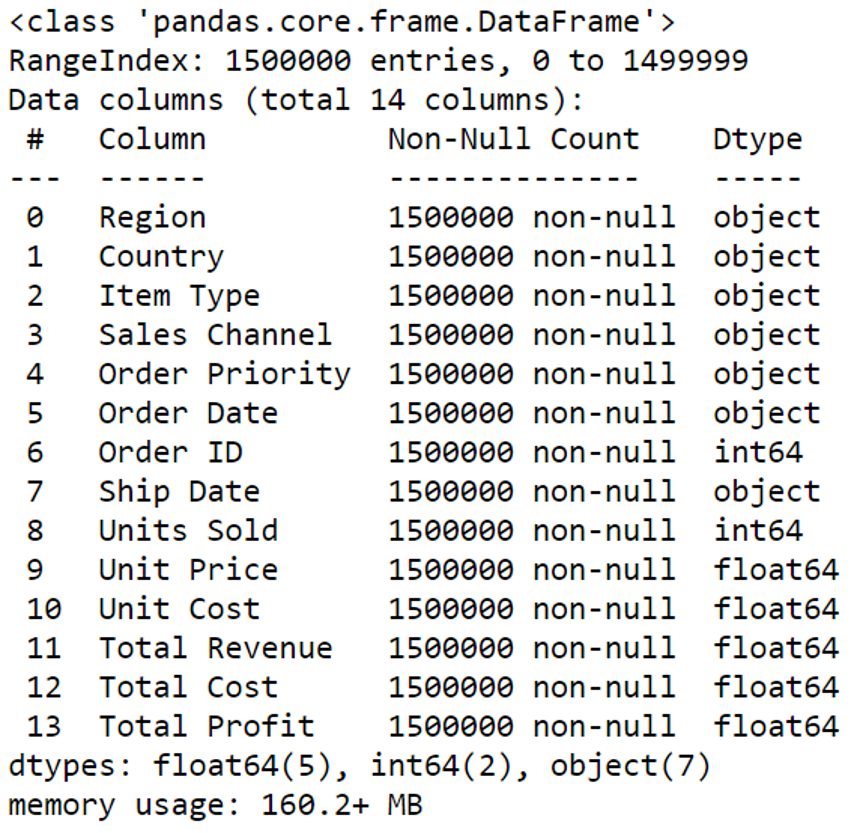
และเราสามารถดูชื่อของคอลัมน์ พร้อมประเภทตัวแปรได้ด้วยการใช้คำสั่ง df.info() ในตอนนี้เราทราบว่าบางคอลัมน์มีประเภทของข้อมูลที่ไม่ถูกต้อง เช่น {Order Date} , {Ship Date} ซึ่งเป็น object แทนที่จะเป็น datetime หรือแม้กระทั่ง {Order ID} ที่ตามหลักการเก็บข้อมูลควรจะเก็บเป็น string หรือ object แต่โปรแกรมมองว่ามันเป็น integer ในส่วนของขนาด DataFrame จะอยู่ที่ประมาณ 160.2 MB
df.info()output:
3. Build Sample Scripts for Data Processing
เมื่อทราบถึงลักษณะของข้อมูลแล้ว เราจะทำการยกตัวอย่างสถานการณ์การเตรียมข้อมูลดังนี้
ข้อมูลจะถูกตัดให้เหลือแค่ 1 ล้านแถว
คอลัมน์ {Order Priority}, {Unit Price}, {Unit Cost}, {Total Cost}, {Total Profit} จะถูกตัดออก
คอลัมน์ {Order ID} จะถูกแปลงเป็น string/object
คอลัมน์ {Order Date}, {Ship Date} จะถูกแปลงเป็น datetime
กระบวนทั้งหมดนี้จะถูกทำด้วยสองวิธีคือ 1. Read-then-process 2. Read-and-process เพื่อเปรียบเทียบกัน
Method 1: read-then-process
วิธีนี้คือการอ่านไฟล์แล้วค่อยทำการเตรียมข้อมูลทีหลัง โดยจะใช้หลายๆ ฟังก์ชั่นมาประกอบกันมีรายละเอียดดังนี้
1.1 สำหรับวิธีนี้เราจะเริ่มด้วยการอ่านไฟล์กันก่อน โดยใช้คำสั่ง pd.read_csv()
df = pd.read_csv('dataset/1500000SalesRecords.csv')
1.2 ตัดให้เหลือ 1 ล้านแถว
df = df.head(1000000)
1.3 คัดเอาเฉพาะคอลัมน์ที่จำเป็นด้วยการ subset by columns
df = df[[
'Region', 'Country', 'Item Type',
'Sales Channel', 'Order Date',
'Order ID', 'Ship Date', 'Units Sold',
'Total Revenue'
]]1.4 แปลงประเภทข้อมูลของคอลัมน์ {Order ID} โดยใช้วิธี astype()
df['Order ID'] = df['Order ID'].astype(str)1.5 แปลงประเภทข้อมูลของคอลัมน์ {Order Date} และ {Ship Date} โดยใช้วิธี pd.to_datetime()
# order date casting
df['Order Date'] = pd.to_datetime(df['Order Date'])
# shipe date casting
df['Ship Date'] = pd.to_datetime(df['Ship Date'])Method 2: read-and-process
วิธีนี้คือการอ่านไฟล์พร้อมกับการเตรียมข้อมูล โดยจะใช้ pd.read_csv() เป็นฟังก์ชั่นหลัก แต่จะประกอบด้วย data structure เสริมคือ list และ dictionary รวมถึงฟังก์ชั่นที่ช่วยในการแปลงค่าของคอลัมน์วันที่ code โดยรวมจะเป็นดังนี้
# set column names
cols = [
'Region', 'Country', 'Item Type',
'Sales Channel', 'Order Date', 'Order ID',
'Ship Date', 'Units Sold', 'Total Revenue'
]
# date parser
from datetime import datetime
dateparse = lambda x: datetime.strptime(x, '%m/%d/%Y')
# read data file
df = pd.read_csv(
'dataset/1500000SalesRecords.csv',
nrows=1000000, usecols=cols,
dtype={'Order ID': str},
parse_dates=['Order Date', 'Ship Date'],
date_parser=dateparse
)เราจะมาดูรายละเอียดกันทีละส่วน โดยเริ่มต้นจากการดู documentation ของ pd.read_csv() ก่อน จะเห็นว่ามี input parameters ให้เลือกใช้หลายตัวมาก ครอบคลุมในส่วนของการกำหนดจำนวนคอลัมน์ จำนวนแถว ประเภทของข้อมูลในแต่ละคอลัมน์ การอ่านคือสูญหาย (missing data) การอ่านวันที่ และอื่นๆ อีกมากมาย

2.1 การกำหนดจำนวนแถวที่ต้องการอ่านข้อมูล
เราจะใช้ parameter ที่ชื่อว่า nrows ในการกำหนดจำนวนแถว ซึ่งเท่ากับ 1 ล้าน

nrows = 10000002.2 การกำหนดคอลัมน์ที่ต้องการอ่านข้อมูล
สำหรับการกำหนดขอบเขตของคอลัมน์ที่ต้องการอ่าน เราใช้สนใจ paremeter ที่ชื่อว่า usecols ซึ่งรับค่าของ list เข้าไปเพื่อกำหนดคอลัมน์ โดยจะใส่เป็นชื่อคอลัมน์ หรือจะเป็น index ของคอลัมน์ก็ได้
# usecols : list - like, or callable, optionalในกรณีนี้ เราจะใส่ชื่อของคอลัมน์ที่ต้องการเข้าไป ด้วยการสร้าง list ชื่อว่า cols
cols = [
'Region', 'Country', 'Item Type',
'Sales Channel', 'Order Date', 'Order ID',
'Ship Date', 'Units Sold', 'Total Revenue'
]
usecols=cols2.3 แปลง {Order ID} เป็น object/string
เราต้องมองหา parameter ที่ชื่อว่า dtype ซึ่งกำหนดว่าให้รับค่า dictionary เข้าไป โดยมี key เป็นชื่อคอลัมน์ และ value เป็นประเภทของตัวแปรที่ต้องการ การทำเช่นนี้เท่ากับเป็นการบังคับให้โปรแกรมกำหนดค่าของตัวแปรให้ตามที่เราต้องการ แทนที่จะประเมินด้วยตัวมันเอง
# dtype : Type name or dict of column -> type, optionalในกรณีนี้ {Order ID} จะถูกตั้งค่าให้เป็น string
dtype = {'Order ID': str}2.4 แปลงคอลัมน์วันที่เป็น datetime
หลายคนอาจจะสงสัยว่าทำไมเราถึงไม่ใช่ dtype เลย คำตอบก็คือว่า วันที่นั้นต้องถูกอ่านด้วยวิธีพิเศษซึ่งเรียกว่าการ parse เพราะเราต้องกำหนดให้โปรแกรมสามารถมองหา วัน เดือน ปี ได้อย่างถูกต้องด้วยการกำหนด date format ซึ่งการจะอ่านวันที่ได้นั้นต้องใช้ parameters 2 ตัวได้แก่ parse_dates เพื่อกำหนดชื่อคอลัมน์เป้าหมาย และ date_parser เพื่อกำหนดวิธีการอ่าน
# parse_dates : bool or list of int or names or list of lists or dict, default False# date_parser : function, optionalในกรณีนี้ parse_dates ของเราก็คือ list ของคอลัมน์ Order Date และ Ship Date
parse_dates = ['Order Date', 'Ship Date']ส่วน date_parser ก็คือ function ที่อ่าน format เป็น mm/dd/year ซึ่งเราสร้างเป็น lambda function
from datetime import datetime
dateparse = lambda x: datetime.strptime(x, '%m/%d/%Y')4. Build a Script for Performance Measurement
เพื่อให้การทดสอบของเรานั้นสามารถวัดผลได้ เราจะสร้าง script มาตรฐานขึ้นเพื่อใช้จับเวลาและดูขนาด object ในการรันโปรแกรม โดยมีโครงร่างการทำงานโดยสังเขปดังนี้
1. Import time and pandas modules
เราใช้ time.time() ในการจับเวลาตั้งเริ่มรันโปรแกรมจนถึงสิ้นสุด และเรายัง set ค่า display width = None เพื่อให้เราสามารถมองเห็นทั้ง dataframe ได้ในการแสดงผล
# imports
import time
import pandas as pd
pd.set_option('display.width', None) # to see all columns2. Start timer
print('Method 2: Starting Experiment')
# timer starts
start = time.time()3. Do data processing
ในส่วนนี้เราใส่ code ที่เรา developed เอาไว้ก่อนหน้า โดยแบ่งเป็นสองไฟล์ python script สำหรับวิธีการที่ 1 และ 2
4. Show results
ผลการทดลองจะถูกแสดง ทั้งในส่วนของหน้าตาของข้อมูลที่ผ่านกระบวนการ ขนาดไฟล์ และระยะเวลาในการทำงานทั้งหมด
# display information
print('Show Infos:')
df.info()
print('')
print('Show Top Three Rows')
print(df.head(3))
# timer ends
end = time.time()
print('\nExperiment Completed\nTotal Time: {:.2f} seconds'.format(end-start))โค้ดของแต่การทดลองจะออกมามีหน้าตาดังนี้
(สามารถไปดาวน์โหลดได้จาก github เพื่อลองมารันเองได้เช่นกัน
Method #1
## read_csv experiment
## method 1: read-then-process
# imports
import time
import pandas as pd
pd.set_option('display.width', None) # to see all columns
print('Method 1: Starting Experiment')
# timer starts
start = time.time()
# read data file
df = pd.read_csv('dataset/1500000SalesRecords.csv')
# processing data
# select top 1M
df = df.head(1000000)
# select some columns
df = df[[
'Region', 'Country', 'Item Type',
'Sales Channel', 'Order Date', 'Order ID',
'Ship Date', 'Units Sold', 'Total Revenue'
]]
# order ID casting
df['Order ID'] = df['Order ID'].astype(str)
# order date casting
df['Order Date'] = pd.to_datetime(df['Order Date'])
# ship date casting
df['Ship Date'] = pd.to_datetime(df['Ship Date'])
# display information
print('Show Infos:')
df.info()
print('')
print('Show Top Three Rows')
print(df.head(3))
# timer ends
end = time.time()
print('\nExperiment Completed\nTotal Time: {:.2f} seconds'.format(end-start))Method #2
## read_csv experiment
## method 2: read-and-process
# imports
import time
import pandas as pd
pd.set_option('display.width', None) # to see all columns
print('Method 2: Starting Experiment')
# timer starts
start = time.time()
# set column names
cols = [
'Region', 'Country', 'Item Type',
'Sales Channel', 'Order Date', 'Order ID',
'Ship Date', 'Units Sold', 'Total Revenue'
]
# date parser
from datetime import datetime
dateparse = lambda x: datetime.strptime(x, '%m/%d/%Y')
# read data file
df = pd.read_csv(
'dataset/1500000SalesRecords.csv', nrows=1000000, usecols=cols,
dtype={'Order ID': str},
parse_dates= [
'Order Date', 'Ship Date'
],
date_parser=dateparse
)
# display information
print('Show Infos:')
df.info()
print('')
print('Show Top Three Rows')
print(df.head(3))
# timer ends
end = time.time()
print('\nExperiment Completed\nTotal Time: {:.2f} seconds'.format(end-start))5. Results and conclusion remarks
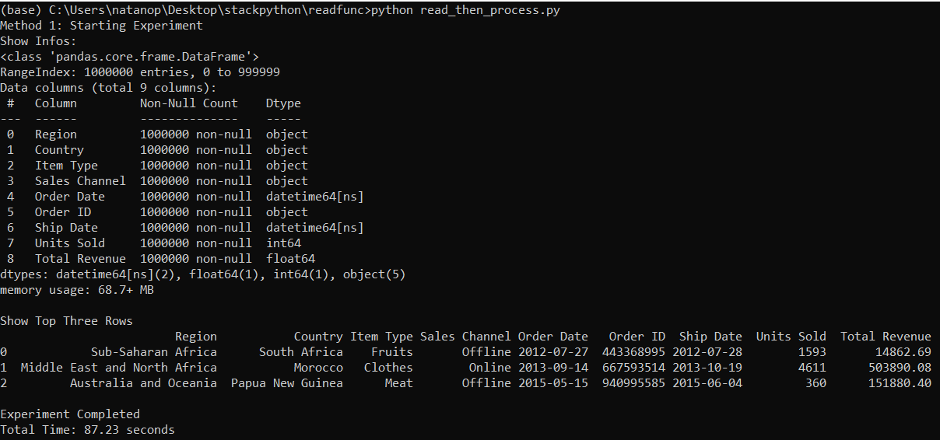
เมื่อได้ทำการรันทั้ง 2 script แล้ว จุดที่แตกต่างที่สุดก็คือเรื่องของระยะเวลาที่ใช้ในการรัน โดย method 1 จะใช้เวลาอยู่ที่ประมาณ 87 วินาที ในขณะที่ method 2 จะใช้อยู่เพียงแค่ 15 วินาที เท่านั้น
Method #1: Read-then-process
Method #2: Read-and-process
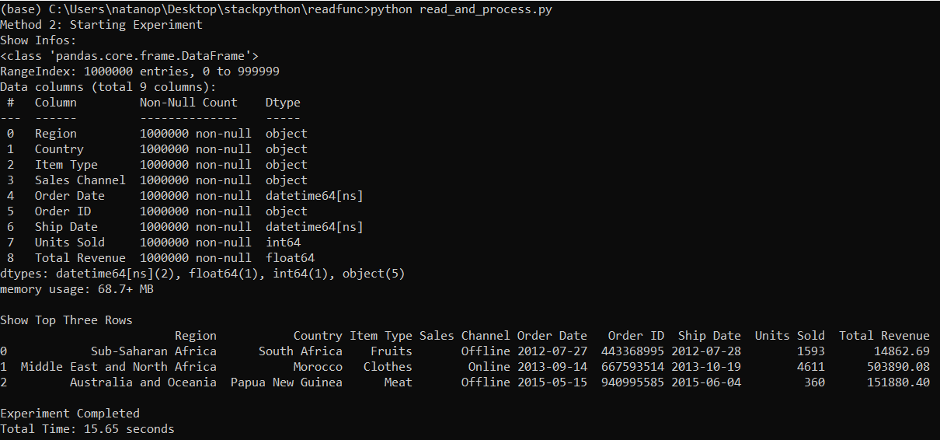
ในส่วนของขนาด object ในขั้นสุดท้ายนั้น ทั้งสองวิธีจะให้ขนาดที่เท่ากันอยู่ที่ประมาณ 68.7 MB ซึ่งควรจะเท่ากันทั้งสองวิธี เพราะเรากำหนดให้โปรแกรมทำงานและให้ผลลัพธ์ที่เหมือนกัน
สำหรับการเขียนโปรแกรม วิธีการที่ 2 จะใช้จำนวนบรรทัดของโค้ดน้อยกว่าและสามารถ maintain ได้สะดวกกว่าเพราะทุกอย่างรวมอยู่ในฟังก์ชั่น read_csv() เพียงอย่างเดียว แต่อาจจะมีความยากต่อใช้งานที่ต้องทราบพื้นฐานเรื่องการอ่านวันที่ หรือการใช้งาน list และ dictionary นอกเหนือจากนี้หากเราต้องการทำจะการวิเคราะห์ข้อมูลเพิ่มเติม
จากข้อมูลทั้งหมดนี้ เราอาจจะสรุปได้ว่าการ read-and-process data ไปในขั้นตอนเดียวกันเลยนั้นจะมีความสะดวกมากกว่าในแง่ของระยะเวลาในการรัน ซึ่งเหมาะสมกับการนำไปใช้ในการทำ production อย่างไรก็ตาม หากชุดข้อมูลดังกล่าวยังอยู่ในช่วงการ exploration หรือทดสอบอยู่ การอ่านไฟล์ทั้งหมดแล้วค่อยนำมา process ตามที่ต้องการอาจจะเป็นวิธีที่ดีกว่า
ประโยชน์ของการใช้งาน pd.read_csv() หรือ pd.read_excel() ยังมีอีกมาก เช่นการกำหนดแถวของ header การอ่านข้อมูลเป็นชุดๆ ด้วยการกำหนด chunk size เพื่อป้องกัน memory error ซึ่งก็จะได้กล่าวถึงในโอกาสต่อไปครับ
Try it yourself by pulling from github Readcsvtests
กิจกรรมที่กำลังจะมาถึง
ไม่พลาดกิจกรรมเด็ด ๆ ที่น่าสนใจ
Python Bundle 2023 สมัครครั้งเดียวเรียนได้ทุกคอร์ส
Event นี้จะเริ่มขึ้นใน April 25, 2023
รายละเอียดเพิ่มเติม/สมัครเข้าร่วมคำอธิบาย
คอร์สเรียนไพธอนออนไลน์ที่เราได้รวบรวมและได้ย่อยจากประสบการณ์จริงและเพื่อย่นระยะเวลาในการเรียนรู้ ลองผิด ลองถูกด้วยตัวเองมาให้แล้ว เพราะเวลามีค่าเป็นอย่างยิ่ง พร้อมด้วยการซัพพอร์ตอย่างดี